nba运动员追踪系统 用Python追踪NBA球员的运动轨迹

编译|黄念程序注释|席雄芬动画效果| 顾运筠校对|丁一,姚佳灵
编辑按:
我曾是个狂热的飞人乔丹的球迷。当年,几乎看了他的每一场比赛!看NBA的比赛是我生命中不可缺少的部分,这是我看到这个利用Python写NBA球员系列时,特别感兴趣的原因。希望这个系列能带给大家一点关于NBA的知识。同时为中国男篮再次获得亚锦赛冠军喝彩!什么时候,我们的CBA也提供这么详细的数据让大家研究一下队员就好了。
文摘曾于8月18日发布《如何运用Python绘制NBA投篮图表》,与本文有直接联系,点击文章名称可回顾旧文。
在本文中,我将介绍如何在stats.nba.com上的比赛运动动画中提取一些额外的信息。
In[1]:

In[2]:

我们将从一场比赛中提取信息。这是快船队(Clippers)和火箭队(Rockets)在季后系列赛的第5场比赛。在比赛中,James Harden瓦解了快船队的防守,冲向篮筐,把球传给Trevor Ariza,轻松获得3分。
我已经在下面嵌入了运动动画。
In[3]:

输出是一个动画
获取数据
下面是我们从stats.nba.com的应用程序接口获取数据的链接。链接里有2个参数:eventid是特定比赛的ID,gameid则是季后赛的ID。
In[4]:

我们发出请求提取数据
In[5]:

Out[5]:
我们想要的数据在:home (主场球员的数据),visitors (客场球员的数据),和moments (使用于动画中用于绘制球员运动轨迹信息的数据)
In[6]:

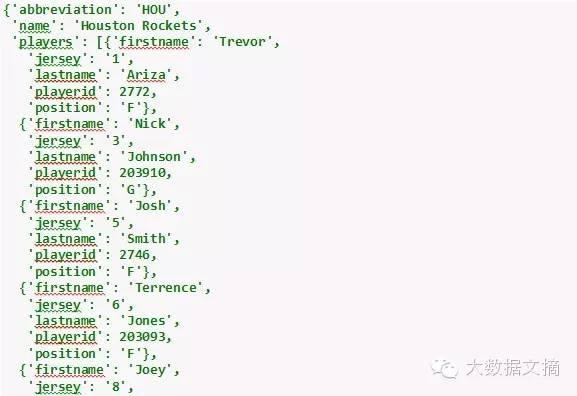
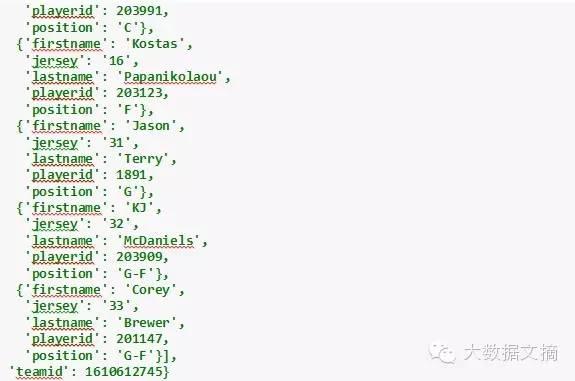
让我们看看home字典里包含的信息。
In [7]:
home
Out[7]:

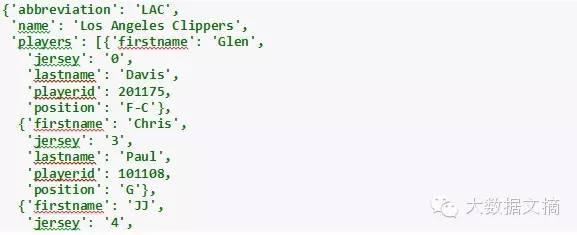
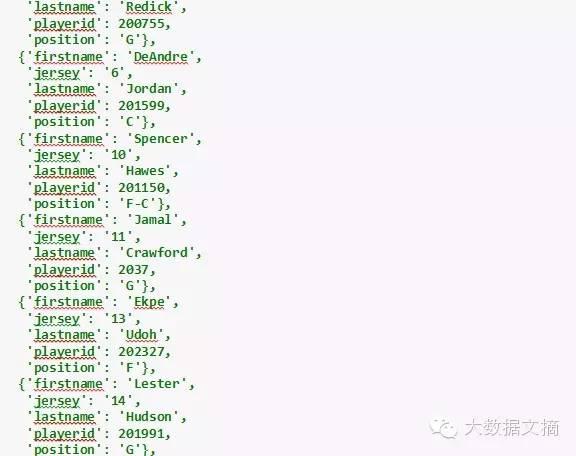
Visitor字典包含了关于快船队的同样类型的信息。
In[8]:
visitor
Out[8]:
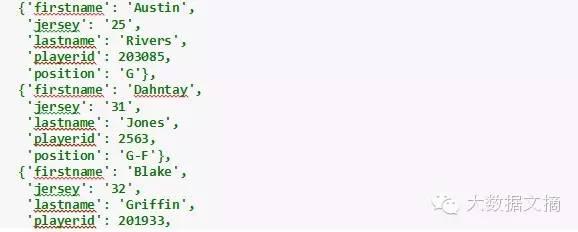
现在,让我们看看moments列表。
In [9]:
#检查长度
len(moments)
Out[9]:
700
长度告诉我们,上面的动画由700个项目/时刻组成。但是,都有些什么信息呢?让我们来看看第一个。
In [10]:
moments[0]
Out[10]:
[3,
1431486313010,
715.32,
19.0,
,
[[-1, -1, 43.51745, 10.76997, 1.11823],
[1610612745, 1891, 43.21625, 12.9461, 0.0],
[1610612745, 2772, 90.84496, 7.79534, 0.0],
[1610612745, 2730, 77.19964, 34.36718, 0.0],
[1610612745, 2746, 46.24382, 21.14748, 0.0],
[1610612745, 201935, 81.0992, 48.10742, 0.0],
[1610612746, 2440, 88.12605, 11.23036, 0.0],
[1610612746, 200755, 84.41011, 43.47075,0.0],
[1610612746, 101108, 46.18569, 16.49072,0.0],
[1610612746, 201599, 78.64683, 31.87798,0.0],
[1610612746, 201933, 65.89714, 25.57281,0.0]]]
首先,我们看到moments中的时刻或项目是一个包含了一堆信息的列表。我们逐一查看列表中的每一个项目。
1 moments[0]中的第1项是这一刻所发生的时期或季度。
2 Unix时间。(是一种时间表示方式,定义为从格林威治时间1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒——译者注)
3第3项是指比赛剩下的时间。
4第4项是指计时器剩下的时间。
5我不知道第5项代表什么。
6第6项是由11个子列表组成的列表,每个子列表包含球场上某个球员或球的坐标。
6.1 11个子列表中的第1个包含了球的信息。
6.1.1前2项是表示teamid和playerid的值,用于表明该列表是关于球的信息。
6.1.2接下来的2项则是x和y坐标值,用于表示球场中球的位置。
6.1.3第5项(最后一项)是代表球的半径。这个值在整个动画中都随着球的高度而变化。半径越大,球就越高。因此,如果球员投篮,球的大小就会增加,在拍摄弓的顶点达到其最大值,然后随着高度下降,球逐渐变小。
6.2第6项中的10个列表表示球场上的10名球员。在这些列表中,关于球的信息是一样的。
6.2.1前2项是teamid和playerid,表示这是某个特定球员的列表。
6.2.2接下来的2项则是x和y坐标值,代表该球员在球场上的位置。
6.2.3最后1项是球员的活动半径,这是不相关的信息。
现在我们对moments数据所代表的信息有了一定的理解。我们把它输入pandas DataFrame。
首先我们创建DataFrame的列标签。
In[11]:
#列标签
headers =["team_id", "player_id", "x_loc","y_loc",
"radius","moment", "game_clock", "shot_clock"]
然后,我们为每个球员创建一个包含moments数据的单独列表。
In[12]:
#初始化新列表player_moments
player_moments= []
for momentin moments:
#对列表中的每个球员/进球找到相应的moments
for player in moment[5]:
#对每个球员/进球增加额外的信息,包括每个moment的索引。比赛时间,投篮时间
player.extend((moments.index(moment),moment[2], moment[3]))
player_moments.append(player)
In[13]:
#查看moments列表
player_moments[0:11]
Out[13]:
[[-1, -1,43.51745, 10.76997, 1.11823, 0, 715.32, 19.0],
[1610612745, 1891, 43.21625, 12.9461, 0.0, 0,715.32, 19.0],
[1610612745, 2772, 90.84496, 7.79534, 0.0, 0,715.32, 19.0],
[1610612745, 2730, 77.19964, 34.36718, 0.0, 0,715.32, 19.0],
[1610612745, 2746, 46.24382, 21.14748, 0.0, 0,715.32, 19.0],
[1610612745, 201935, 81.0992, 48.10742, 0.0,0, 715.32, 19.0],
[1610612746, 2440, 88.12605, 11.23036, 0.0, 0,715.32, 19.0],
[1610612746, 200755, 84.41011, 43.47075, 0.0,0, 715.32, 19.0],
[1610612746, 101108, 46.18569, 16.49072, 0.0,0, 715.32, 19.0],
[1610612746, 201599, 78.64683, 31.87798, 0.0,0, 715.32, 19.0],
[1610612746, 201933, 65.89714, 25.57281, 0.0,0, 715.32, 19.0]]
将刚刚创建的moments列表和我们的列标签传给pd.DataFrame,创建我们的DataFrame。
In[14]:
#将Player_moments列表转化为数据框形式
df =pd.DataFrame(player_moments, columns=headers)
In [15]:
df.head(11)
Out[15]:
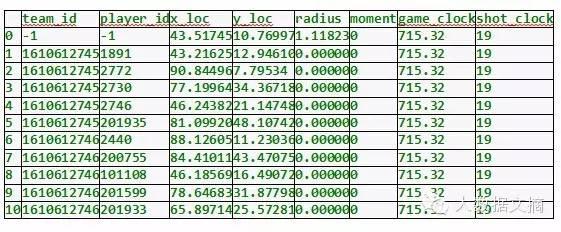
我们还没有完成。我们应添加包含球员姓名和球衣号码的列。首先,将所有的球员放入一个列表。
In[16]:
#创建player列表,将主队运动员的数据赋值给player
players =home["players"]
#添加客队运动员的数据
players.extend(visitor["players"])
利用players列表,我们可以创建一个以球员ID作为关键字的字典和一个包含球员姓名和球衣号码的值列表。
In[17]:
#创建新的字典id_dict
id_dict ={}
#在字典中增加我们想要的值,
for playerin players:
id_dict[player['playerid']] =[player["firstname"]+""+player["lastname"],player["jersey"]]
In [18]:
id_dict
Out[18]:
{1891:['Jason Terry', '31'],
2037: ['Jamal Crawford', '11'],
2045: ['Hedo Turkoglu', '15'],
2440: ['Matt Barnes', '22'],
2563: ['Dahntay Jones', '31'],
2730: ['Dwight Howard', '12'],
2746: ['Josh Smith', '5'],
2772: ['Trevor Ariza', '1'],
101108: ['Chris Paul', '3'],
200755: ['JJ Redick', '4'],
201147: ['Corey Brewer', '33'],
201150: ['Spencer Hawes', '10'],
201175: ['Glen Davis', '0'],
201595: ['Joey Dorsey', '8'],
201599: ['DeAndre Jordan', '6'],
201933: ['Blake Griffin', '32'],
201935: ['James Harden', '13'],
201991: ['Lester Hudson', '14'],
202327: ['Ekpe Udoh', '13'],
203085: ['Austin Rivers', '25'],
203093: ['Terrence Jones', '6'],
203123: ['Kostas Papanikolaou', '16'],
203143: ['Pablo Prigioni', '9'],
203909: ['KJ McDaniels', '32'],
203910: ['Nick Johnson', '3'],
203991: ['Clint Capela', '15']}
我们更新id_dict,纳入球的ID。
In[19]:
#将球的ID纳入字典中
id_dict.update({-1:['ball', np.nan]})
然后利用位映象法对应player_id列创建player_name列和一个player_jersey。我们用lambda,位映像一个匿名函数,根据传给函数的player_id值而返回正确的player_name和player_jersey。
换句话说,下面的代码所做的是遍历player_id列中的球员ID,然后把每个球员ID传递给那个匿名函数。这个函数返回的是球员的名字以及该球员的球衣号码,并把这些值添加到我们的DataFrame中。
In [20]:
#创建与player_id匹配的player_name和player_jersey列
df["player_name"]= df.player_id.map(lambda x: id_dict[x][0])
df["player_jersey"]= df.player_id.map(lambda x: id_dict[x][1])
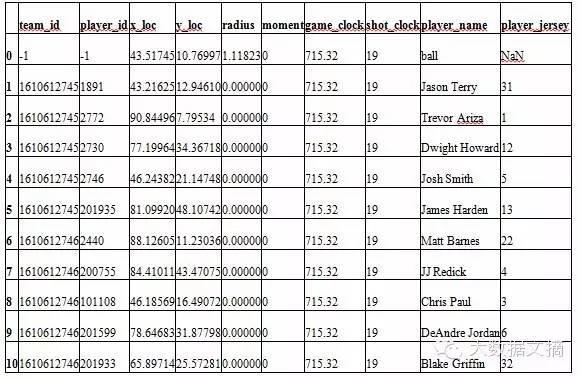
In [21]:
#显示df数据框的前11行
df.head(11)
Out[21]:
绘制运动轨迹
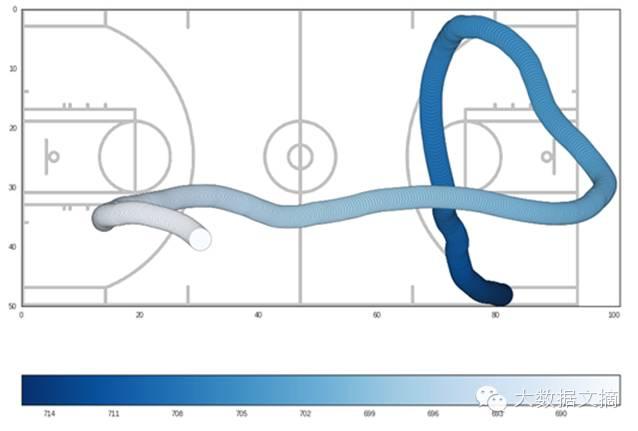
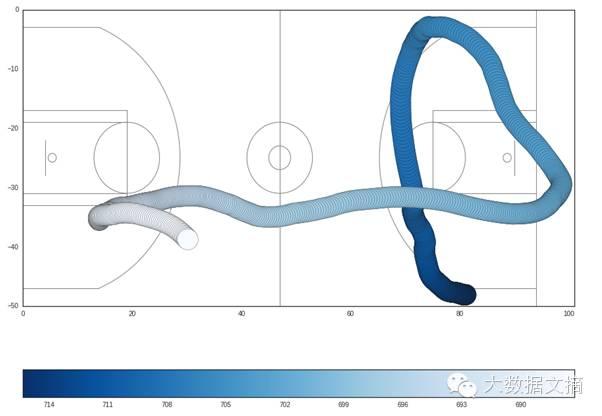
绘制James Harden在整个比赛中的运动轨迹。我们可以借助从stas.nba.com获取的球场图片来绘制球场。你可以在上面找到SVG。我用matplotlib将其转换成PNG文件,从而使其更容易绘制。此外,还应注意x或y轴上每1单位代表篮球场上的1英尺。
In[22]:
#获取Harden的运动轨迹
harden =df[df.player_name=="James Harden"]
#读取fullcourt.png图片
court =plt.imread("fullcourt.png")
In [23]:

我们也可以通过matplotlib Patches重新创建大部分的球场。我们不是使用SVG坐标系统,而是使用经典的直角坐标系统。因此,我们的y轴值将是负值,而非正值。
In[24]:

In [25]:
plt.figure(figsize=(15,11.5))
#画出movemnts的散点图
#使用colormap表示比赛时的变化
plt.scatter(harden.x_loc,-harden.y_loc, c=harden.game_clock,
cmap=plt.cm.Blues, s=1000,zorder=1)
#颜色越深表示移动轨迹越早
cbar =plt.colorbar(orientation="horizontal")
#逆转colorbar让左侧区域有较高的值
cbar.ax.invert_xaxis()
draw_court()
plt.xlim(0,101)
plt.ylim(-50,0)
plt.show()
计算运动距离
通过得到连续点之间的欧式距离(Euclidean distance是一个通常采用的距离定义,它是在m维空间中两个点之间的真实距离。——译者注),然后对这些距离求和,我们可以算出一个球员运动的距离。
In[26]:
deftravel_dist(player_locations):
#对每一列差分相减求误差
diff = np.diff(player_locations, axis=0)
#将误差平方相加再开方
dist = np.sqrt((diff ** 2).sum(axis=1))
#返回所有距离的和
returndist.sum()
In [27]:
# Harden'的运动距离
dist =travel_dist(harden[["x_loc", "y_loc"]])
dist
Out[27]:
197.44816608512659
我们可以使用groupby和apply得到每个球员的运动总距离。我们将球员分组,得到他们每个的坐标位置,然后应用上述距离函数。
In[28]:
#使用groupby和apply得到每个球员的运动总距离
player_travel_dist= df.groupby('player_name')[['x_loc', 'y_loc']].apply(travel_dist)
player_travel_dist
Out[28]:
player_name
BlakeGriffin 153.076637
ChrisPaul 176.198330
DeAndreJordan 119.919877
DwightHoward 123.439590
JJRedick 184.504145
JamesHarden 197.448166
JasonTerry 173.308880
JoshSmith 162.226100
MattBarnes 161.976406
TrevorAriza 153.389365
ball 328.317612
dtype:float64
计算平均速度
计算球员的平均速度相当简单:只需将距离除以时间即可。
In[29]:
#获取比赛的时长
seconds =df.game_clock.max() - df.game_clock.min()
#以每秒英尺为单位
harden_fps= dist / seconds
#转化为每小时英里为单位
harden_mph= 0.681818 * harden_fps
harden_mph
Out[29]:
4.7977089702005902
我们可以使用先前创建的player_travel_dist得到每个球员的平均速度。
In[30]:
#计算每个球员的平均速度
player_speeds= (player_travel_dist/seconds) * 0.681818
player_speeds
Out[30]:
player_name
BlakeGriffin 3.719544
ChrisPaul 4.281368
DeAndreJordan 2.913882
DwightHoward 2.999406
JJRedick 4.483188
JamesHarden 4.797709
JasonTerry 4.211159
JoshSmith 3.941863
MattBarnes 3.935796
TrevorAriza 3.727143
ball 7.977650
dtype:float64
计算球员之间的距离
让我们来看看比赛中Harden与其他每一个球员之间的距离。
首先得到Harden的位置。
In[31]:
#获取Harden的位置
harden_loc= df[df.player_name=="James Harden"][["x_loc","y_loc"]]
In [32]:
harden_loc.head()
Out[32]:
x_locy_loc581.0992048.107421681.0199648.115802780.9397648.122793880.8596448.125974980.7743548.12823
现在,我们以player_name分组,得到每个球员和球的位置。
In[33]:
group =df[df.player_name!="JamesHarden"].groupby("player_name")[["x_loc","y_loc"]]
我们利用scipy库中的欧几里德函数,在分组中使用它。函数返回一张列表,包含整个比赛中James Harden和其他球员之间的距离。
In[34]:
fromscipy.spatial.distance import euclidean
In [35]:
#在每个moment计算每个球员之间的距离
defplayer_dist(player_a, player_b):
return [euclidean(player_a.iloc[i],player_b.iloc[i])
for i in range(len(player_a))]
每个球员的位置传给player_dist函数里的player_a参数,Harden的位置传给player_b参数。
In[36]:
harden_dist= group.apply(player_dist, player_b=(harden_loc))
In [37]:
harden_dist
Out[37]:

In[38]:
len(harden_dist["ball"])
Out[38]:
690
In [39]:
len(harden_dist["BlakeGriffin"])
Out[39]:
700
现在,我们知道如何得到球员之间的距离。让我们试着看看James Harden的运球对球场上一些空间的影响。
让我们再看一看运动画面,看看在Harden运球过程中发生的情况。
In[40]:
IFrame('http://stats.nba.com/movement/#!/?GameID=0041400235&GameEventID;=308',width=700,height=400)
Out[40]:
当Harden突入篮下,DeAndre Jordan移出Dwight Howards防守的篮下。Matt Barnes切换过来防守Howards(但跌倒),让Ariza攻破。Harden看到Ariza,把球传给了他,Chris Paul试图冲过来防守,Ariza把握住了机会,投篮成功,这一切都发生在第三季度约11分钟46秒到11分钟42秒之间。计时钟从约10.1秒开始计时,那时Harden开始运球,计时到约6分2秒时,Ariza投出球。实际上,我们可以在Ariza的投篮日志页找到更多关于他投球尝试的信息。
In[41]:
#获取特定时间段的数据
time_mask =(df.game_clock = 702) & \\
(df.shot_clock = 6.2)
time_df =df[time_mask]
从动画看,Harden似乎在第四节比赛只剩7.7到7.8秒的时候传了球。我们可以通过查看他和球之间的距离来确认这一情况。
In[42]:
#计算James Harden与球之间的距离
ball =time_df[time_df.player_name=="ball"]
harden2 =time_df[time_df.player_name=="James Harden"]
harden_ball_dist= player_dist(ball[["x_loc", "y_loc"]],
harden2[["x_loc","y_loc"]])
In [43]:

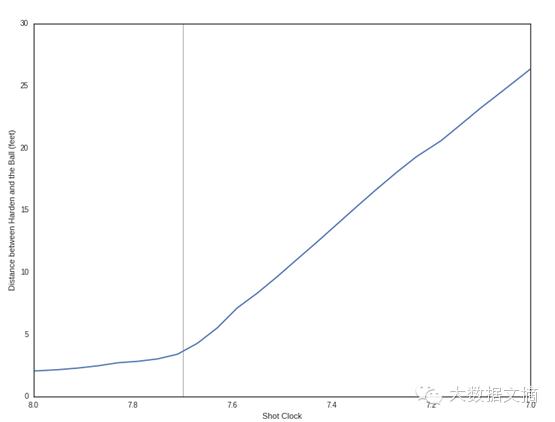
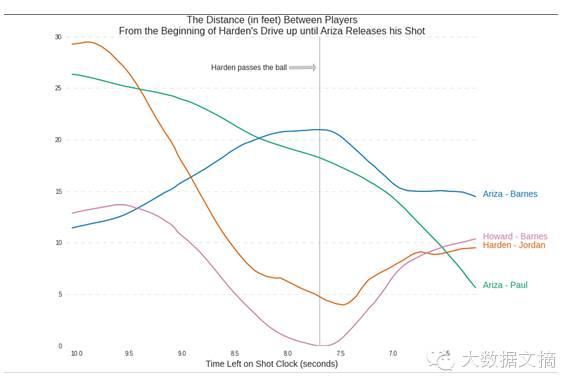
让我们绘制在这段时间内的一些球员之间的距离变化。我们将绘制Harden与Jordan、Howard与Barnes、Ariza与Barnes、Ariza与Paul之间的距离变化。
In[44]:
#获取我们想要的球员信息
player_mask= (time_df.player_name=="Trevor Ariza") | \\
(time_df.player_name=="DeAndre Jordan") | \\
(time_df.player_name=="DwightHoward") | \\
(time_df.player_name=="MattBarnes") | \\
(time_df.player_name=="ChrisPaul") | \\
(time_df.player_name=="JamesHarden")
In [45]:
#获取球员的位置
group2 =time_df[player_mask].groupby('player_name')[["x_loc","y_loc"]]
In [46]:
#获取球员之间的距离差
harden_jordan= player_dist(group2.get_group("James Harden"),
group2.get_group("DeAndre Jordan"))
howard_barnes= player_dist(group2.get_group("Dwight Howard"),
group2.get_group("Matt Barnes"))
ariza_barnes= player_dist(group2.get_group("Trevor Ariza"),
group2.get_group("Matt Barnes"))
ariza_paul= player_dist(group2.get_group("Trevor Ariza"),
group2.get_group("ChrisPaul"))
In [47]:

大数据文摘编译者简介黄念上海长海医院在读硕士,对生物医药大数据挖掘的及其应用很感兴趣,愿意借助本平台认识更多的小伙伴。席雄芬北京邮电大学无线信号处理专业研究生在读,主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣,希望借助此平台能认识更多的从事大数据方面的人,结交更多的志同道合者。顾运筠职业院校的统计老师,对机器学习和数据可视化感兴趣。丁一德罕,杜克大学药理系在读博士,对生物信息学和临床药学的大数据挖掘很感兴趣。姚佳灵家庭主妇,对数据分析和处理很感兴趣,正在努力学习中,希望能和大家多交流。
【限时】2015年9月干货文件打包下载,请点击大数据文摘底部菜单(2015/10/31前)
以上就是nba运动员追踪系统的内容,希望您能喜欢。




